 @seav@en.osm.town
@seav@en.osm.town2024-03-06 04:18:35
Data modeling is hard!
The first photo, uploaded to #WikimediaCommons, is of a painting depicting a Philippines Historical Committee marker (shown in the second photo) that commemorates a public square that is named after a doctor.
The doctor, the plaza, and the marker all have #Wikidata


 @Techmeme@techhub.social
@Techmeme@techhub.social2024-03-02 01:25:50
Filing: The US DOE settles with bitcoin miner Riot Platforms and an industry group, and agrees to cancel its mandatory survey of energy use by crypto miners (Sarah Wynn/The Block)
https://www.theblock.co/post/280257/emerge
 @leodurruti@puntarella.party
@leodurruti@puntarella.party2024-02-26 07:31:54
Many in Myanmar consider fleeing to Thailand to escape conscription into an army they despise
https://apnews.com/article/myanmar-flee-conscription-law-army-thailand-cbf9fa999b8ac828ea3710ac58b2c157

 @cdarwin@c.im
@cdarwin@c.im2024-04-03 02:22:33
Findings, published Jan. 17 in Cell Stem Cell, show that dopamine neurons infected with SARS-CoV-2 stop working and send out chemical signals that cause inflammation.
Normally, these neurons produce dopamine, a neurotransmitter that plays a role in feelings of pleasure, motivation, memory, sleep and movement.
Damage to these neurons is also connected to Parkinson’s disease.
“This project started out to investigate how various types of cells in different organs respond to …

 @poppastring@dotnet.social
@poppastring@dotnet.social2024-03-27 19:35:23
A post from the archive 📫:
Invalid Access to memory location in KUDU App Services
https://www.poppastring.com/blog/invalid-access-to-memory-location-in-kudu-app-services
 @falschgold@mastodon.social
@falschgold@mastodon.social2024-04-29 09:53:57
 @daniel@social.telemetrydeck.com
@daniel@social.telemetrydeck.com2024-03-01 13:36:15
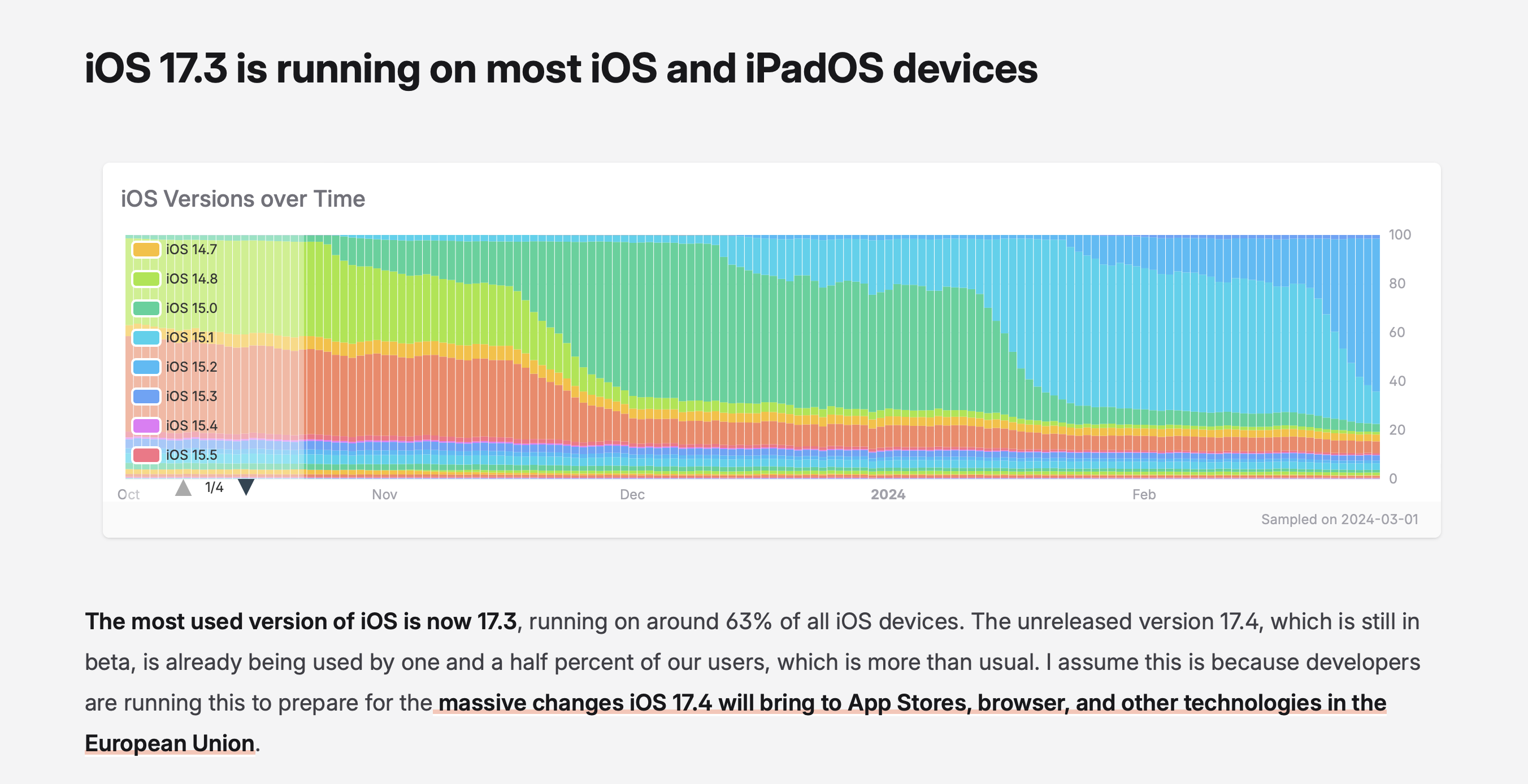
I just really like how colorful this chart is :beardthesystem:
 @frankel@mastodon.top
@frankel@mastodon.top2024-02-26 09:03:04
#Generative AI Conversations using #LangChain4j ChatMemory
https://www.sivalabs.…
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2024-05-01 06:49:06
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
https://arxiv.org/abs/2404.19705 https://arxiv.org/pdf/2404.19705
arXiv:2404.19705v1 Announce Type: new
Abstract: In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
@falschgold@mastodon.social2024-04-29 09:53:57